AI模型中的Token:理解语言模型的基本单位
更新: 3/18/2026字数: 0 字 时长: 0 分钟
在人工智能尤其是大语言模型(LLM)中,“token”是一个非常基础但关键的概念。理解token的概念,对于深入掌握AI模型的工作原理、优化提示词以及控制成本都有重要意义。本文将系统讲解token的定义、作用以及在实际应用中的影响。
一、什么是Token
1.1 基本定义 在自然语言处理(NLP)中,token是指文本的最小处理单位。它可以是:
- 一个单词(如英语中的 “apple”)
- 一个字(如中文的“苹果”可能被分为“苹”“果”)
- 甚至是一个子词或符号(subword)
大语言模型在处理文本时,并不是直接理解整句话,而是先将文本拆分成一系列token,然后基于这些token进行计算和预测。
1.2 为什么不直接用字符或单词
- 字符:单位太小,模型需要处理的序列太长,计算成本高
- 单词:单位太大,可能导致词汇表过大,不易处理罕见词
- token(子词):折中方案,既能表示常见单词,也能拆分罕见词,提高模型效率
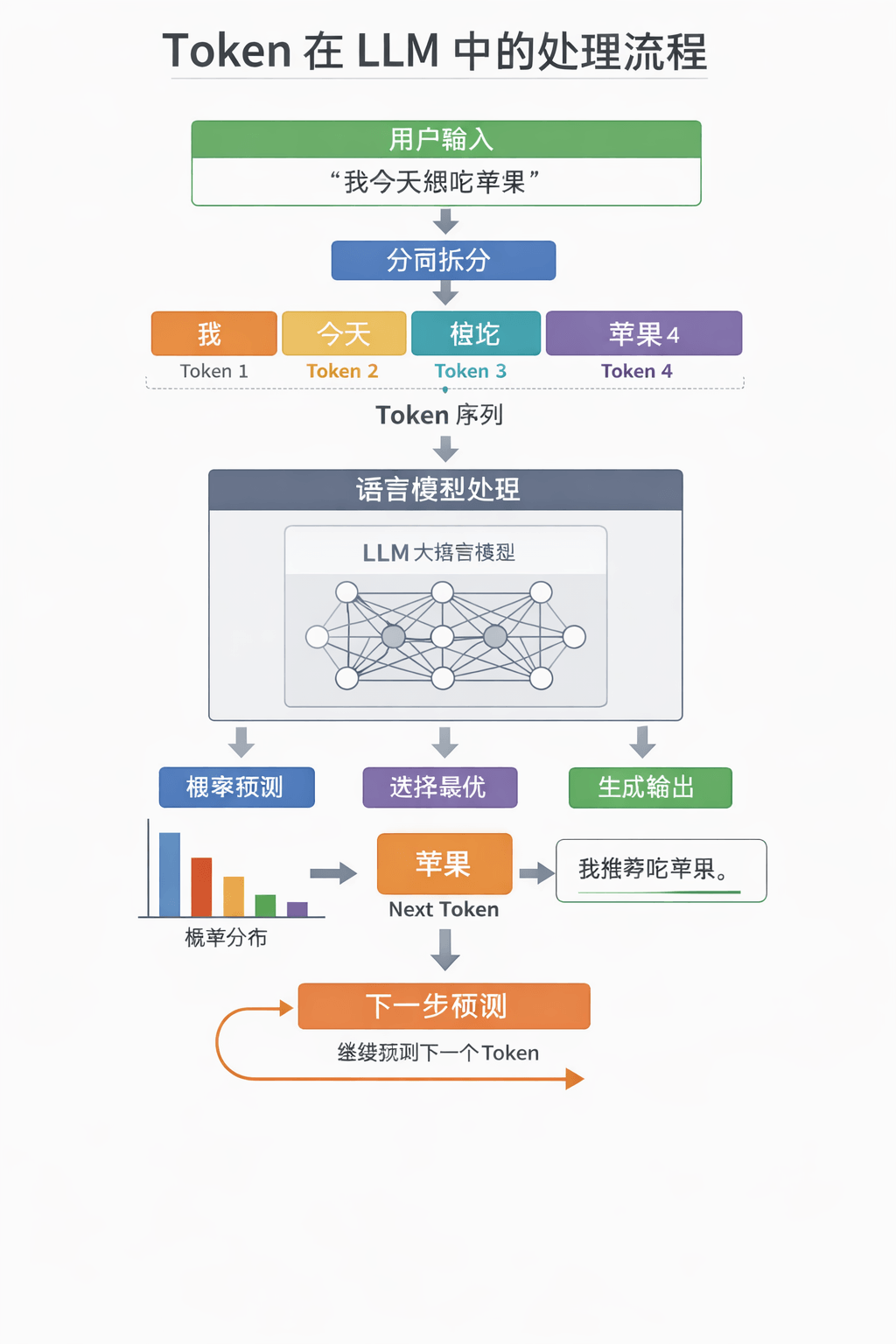
二、Token在模型中的作用
2.1 语言建模的核心 LLM的本质是预测下一个token的概率。也就是说,模型通过上下文,判断下一个token最可能是什么,从而生成自然语言。
示例:
输入:我今天想吃
模型预测下一个token:苹果2.2 序列长度与上下文管理 每个模型都有最大token长度限制,例如GPT-4的上下文窗口可能是8192个token。超出限制的内容可能被截断,因此理解token长度对于处理长文档非常重要。
2.3 成本与消耗 在商用模型中,API调用费用通常按token计费:
- 输入token:用户输入文本被拆分成的token数
- 输出token:模型生成的token数
理解token的拆分方式有助于控制成本,例如将中文文本合理分段、避免冗长提示词。
三、Token与语言差异
不同语言的token长度和拆分方式差异较大:
- 英文:空格天然分词,token通常比单词少
- 中文:没有空格,token通常按字或子词拆分
- 符号与标点:也可能被单独作为token
因此,同样长度的文本,在不同语言中生成的token数量可能差异很大。
四、Token的实际应用场景
4.1 提示词优化(Prompt Engineering) 通过控制token数量,可以:
- 避免超出上下文窗口
- 减少API费用
- 提高模型理解效率
4.2 长文本处理
- 长文档可以先拆成多个token块,再逐块处理
- 使用RAG(检索增强生成)时,将文档切分为token后向量化,以便快速检索
4.3 计量和成本管理
- API费用透明化:根据token数量预测成本
- 可以通过减少无用token和重复文本优化成本
五、总结
Token是大语言模型处理文本的基本单位,它既不是简单的字符,也不是单纯的单词,而是一种折中方式,使模型能够高效地理解和生成自然语言。掌握token的概念和使用方法,有助于:
- 优化提示词设计
- 控制长文本处理策略
- 精准估算模型调用成本
一句话总结:
Token = 模型理解语言的最小单元,是AI生成语言的基础砖块。
图解如下: