模型蒸馏(Model Distillation)
更新: 3/18/2026字数: 0 字 时长: 0 分钟

一、概念
模型蒸馏(Model Distillation)是机器学习中一种模型压缩和知识迁移的方法。
核心思想:用一个“大模型”(Teacher,教师模型)训练一个“小模型”(Student,学生模型),让小模型学到大模型的能力。
目的:
- 减小模型体积 → 更适合部署在手机、边缘设备、IoT等环境。
- 加速推理速度 → 小模型运算快。
- 保持性能 → 尽量保留大模型的预测能力或特征表达。
简单理解:
让“小模型”继承“大模型”的智慧。
二、原理
核心原理是 知识迁移,即把大模型学到的“知识”传给小模型。
具体做法:
大模型预测的概率分布
- Teacher 模型在分类任务中输出 softmax 概率向量。
- 不仅告诉你“类别正确”,还告诉你“各类别的相似度”。
小模型学习这个概率分布
- Student 模型通过最小化与 Teacher 的预测分布的差异来训练。
- 目标函数通常是 KL散度(KL Divergence) 或 交叉熵。
举个例子:
Teacher 模型对一张图片预测:
- 猫:0.7
- 狮子:0.2
- 狗:0.1
Student 模型学习这个分布,而不是只知道“猫是对的”,所以它能捕捉类别之间的细微关系。
三、训练流程
模型蒸馏通常有三种方式:
3.1 软标签蒸馏(Soft Label Distillation)
- 直接使用 Teacher 模型输出的概率作为 Student 的训练目标。
- 优点:简单、直观。
text
流程:
Teacher 模型预测 → 生成软标签 → Student 模型学习软标签3.2 特征蒸馏(Feature Distillation)
- Student 不只学习输出,还学习 Teacher 的中间特征表示(比如隐藏层的向量)。
- 优点:保留更多内部结构知识。
- 常用于 NLP 或计算机视觉中的大模型压缩。
3.3 对抗蒸馏 / 互信息蒸馏
- 利用对抗训练或信息瓶颈的方法,让 Student 学到 Teacher 更高级的分布特征。
- 用于要求高性能的小模型场景。
四、类比理解
为了更直观地理解,可以用“老师教学生”的比喻:
- Teacher(大模型) = 老师
- Student(小模型) = 学生
- 数据 = 教材
- Soft Label / 中间特征 = 老师的讲解和思路
普通训练:
- 学生只看教材自己学 → 很多细节可能学不到
蒸馏训练:
- 学生听老师讲解 → 能快速掌握知识点和思路
- 学生体型小、速度快,但能力接近老师
总结
| 概念 | 解释 |
|---|---|
| Teacher | 大模型,知识源 |
| Student | 小模型,学习目标 |
| Soft Label | Teacher 的输出概率,包含丰富信息 |
| 蒸馏目标 | 让 Student 学到 Teacher 的能力 |
模型蒸馏就是把大模型的“智慧”压缩到小模型,让它轻量化且依然强大。
如图所示: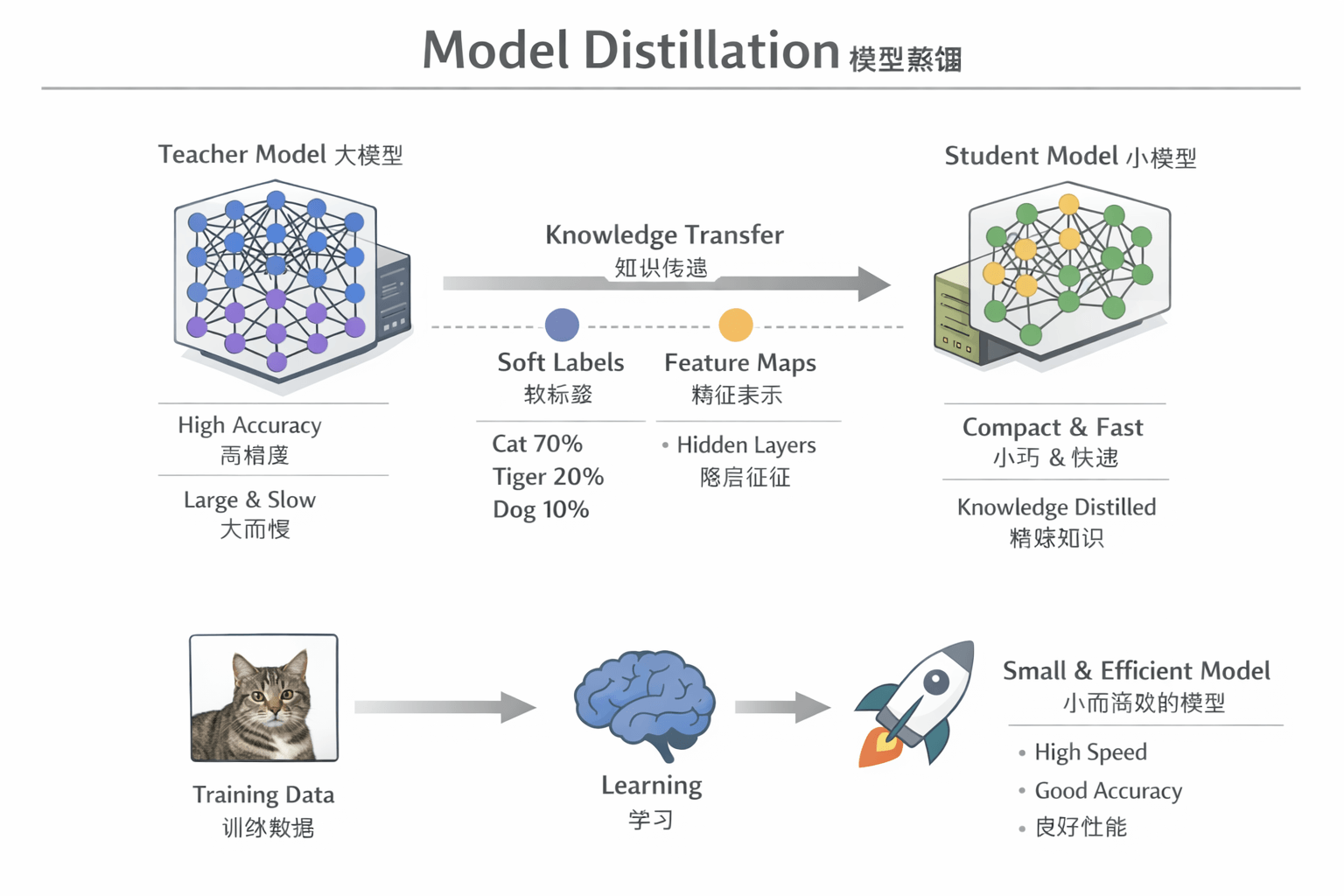
参考网站: